如何使用FiddlerCap抓取网站访问记录
感谢你汇报了有关我的网站或作品的一个问题。为了定位你的问题原因、并尽快解决这个问题,我请求你根据下列步骤抓取一份网站访问记录。
- 下载FiddlerCap,并保存在桌面上
- 请关闭除了本页之外的所有浏览器窗口或标签页
- 双击桌面上的FiddlerCapSetup.exe文件,单击Install按钮
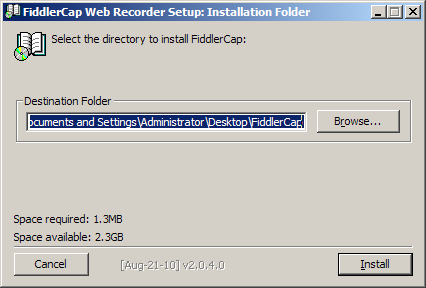
- 安装完毕后,单击Close按钮
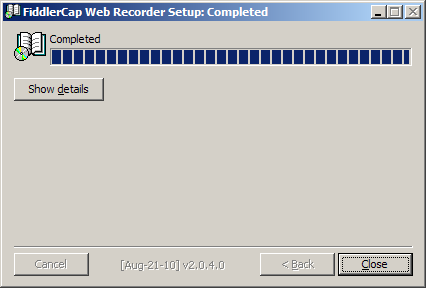
此时如果弹出0xc0000135错误,请下载安装.NET Framework 2.0 - 如果我要求你“抓取HTTPS流量”,请勾选Decrypt HTTPS traffic(弹出A note about HTTPS Decryption对话框请单击OK);勾选此选项后,浏览器访问https网站时会弹出证书错误警告,请忽略那些警告
- 依次单击Clear Cookies、Clear Cache、1 Start Capture按钮

- 如果你使用的浏览器不是IE,请手动将HTTP代理服务器设置成127.0.0.1、端口号8889
- 打开浏览器窗口,访问遇到问题的网页并进行必要的操作,使你汇报的问题再次出现
- 回到FiddlerCap窗口,依次单击2 Stop Capture、3 Save Capture按钮

- 在Save Session Capture to...对话框中,将网站访问记录.saz文件保存在桌面上
- 访问阳光男孩的网上名片查看我的Email地址,并把问题描述、截图、网站访问记录发送给我。
阳光男孩尊重你的隐私,你提交的网站访问记录只会用于问题的定位和解决,不作其他用途。
说明:FiddlerCap是Eric Lawrence编写的HTTP访问记录抓取软件。 本文面向熟悉计算机基本操作的读者,介绍了该软件的基本使用方法,让你在汇报问题时提供更多信息,用于问题的定位和解决。