The OVH fire taught us the importance of having a disaster recovery plan for your website and online services. In 2017, I rebuilt yoursunny.com and moved everything from configuration to content into git repositories. One of the reasons was that, the git repository could serve as a backup of the website, so that I can recover the site from a data loss.
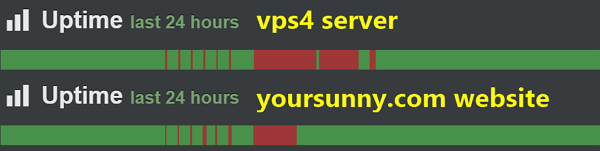
Today, I was forced to execute (part of) my disaster recovery plan. The result was: website is successfully recovered after 1 hour and 44 minutes of downtime.
🟥 Down
When I waked up this morning, there were several alert emails from UptimeRobot telling me that my website was down, up, down, and up again. At the same time, I also received alerts that the VPS hosting the website was not responding to ping. I ignored those alerts, thinking that they would resolve itself in a few minutes.
Some time later, I received another alert:
Probe 1001199 is disconnected (SpartanHost Seattle VPS) Your probe 1001199 has been disconnected from the RIPE Atlas infrastructure since 2021-03-31 12:31:21 UTC.
Some of my servers, including this VPS, are participating in RIPE Atlas, a distributed Internet measurement platform. RIPE Atlas system would send an alert if the software "probe" is disconnected for more than 30 minutes. Receiving this alert email means that my server has been offline for more than 30 minutes.
At that moment, I made a decision: if the downtime reaches one hour, I will re-deploy the website on another server.
🟢 Up
13:41 UTC was when I opened the laptop and started my discovery recovery plan. To re-deploy the website, I need to:
- Decide which server I should use to temporarily host the website.
- Install software needed by the website, which includes Caddy, nginx, and PHP.
- Upload the configuration and content.
- Change DNS records.
Initially, I wanted to deploy the website on a VirMach VPS in Los Angeles. That server has been setup with Debian Buster operating system, and has a lot of spare resources. However, upon opening the software installation instructions for the website, I noticed a problem:
sudo add-apt-repository ppa:nginx/stable
sudo add-apt-repository ppa:ondrej/phpThese commands want to install packages from Ubuntu PPA, which are not compatible with Debian operating system. I can try to identify software sources suitable for Debian, or start from scratch and reinstall the server with Ubuntu, but both options would take much longer.
I searched through other servers I have, and found a server with Ubuntu 20.04 already installed: the Nexril VPS in Dallas. I didn't remember why I setup that server with Ubuntu instead of Debian, but it surely came handy at this moment. I followed the instructions, and got all the software installed in less than 10 minutes.
Content upload was mostly effortless: it's a single rsync command.
However, I had the server IP address hard-coded to a website configuration file, which must be modified before upload.
Finally, I changed the DNS records in Cloudflare control panel to point to the temporary server.
To avoid complication on TLS certificates, I enabled Cloudflare MITM proxy and let Cloudflare provide TLS termination.
Although Caddy can automatically request TLS certificates, I was concerned about possible errors when DNS updates were not fully propagated.
On Cloudflare, I set TLS encryption mode to "full", so that I can use a self signed certificate on the origin server.
Caddy can generate self signed certificate by specifying tls internal directive in Caddyfile.
After 27 minutes of effort, UptimeRobot reported that the website is back online at 14:08 UTC. This downtime started at 12:23 UTC, and lasted 1 hour and 44 minutes.

Root Cause
I posted a thread on the low end hosting forum, titled Spartan Host Seattle knocked offline - no tears. The title is in contrast with the OVH fire thread, "lots and lots of tears". I didn't shed any tears, because I have a disaster recovery plan and I executed it.
The VPS hosting provider, Spartan Host, promptly offered an explanation of their part: a software bug is crashing their Juniper router, so that all the VPS nodes would intermittently lose IP connectivity.
Lessons
I consider a 27-minute manual recovery time good enough. Nevertheless, there are still lessons to be learned:
- I should use Docker containers for nginx and PHP, instead of installing from PPA packages, so that they can work on all operating systems.
- I should have identified which server to use for a temporary deployment a priori, and ensure it has a compatible operating system.
Of course, it's always better to build an automatic failover mechanism, eventually. Otherwise, if the website went down when I'm sleeping or geocaching, I would not be able to spare 27 minutes right away.
P.S. the website has been moved back to the regular server.